返回
2022年08月11日
-
通过网络爬虫采集大数据
网络数据采集是指通过网络爬虫或网站公开 API 等方式从网站上获取数据信息。该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频等文件或附件的采集,附件与正文可以自动关联。
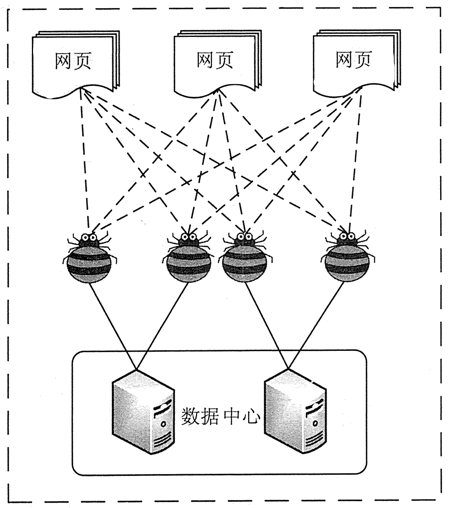
在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。
在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。目前已经知道的各种网络爬虫工具已经有上百个,网络爬虫工具基本可以分为 3 类。
- 分布式网络爬虫工具,如 Nutch。
- Java 网络爬虫工具,如 Crawler4j、WebMagic、WebCollector。
- 非 Java 网络爬虫工具,如 Scrapy(基于 Python 语言开发)。
本节首先对网络爬虫的原理和工作流程进行简单介绍,然后对网络爬虫抓取策略进行讨论,最后对典型的网络工具进行描述。
网络爬虫原理
网络爬虫是一种按照一定的规则,自动地抓取 Web 信息的程序或者脚本。
Web 网络爬虫可以自动采集所有其能够访问到的页面内容,为搜索引擎和大数据分析提供数据来源。从功能上来讲,爬虫一般有数据采集、处理和存储 3 部分功能,如图 1 所示。