返回
2022年08月11日
-
通过系统日志采集大数据
许多公司的平台每天都会产生大量的日志,并且一般为流式数据,如搜索引擎的 pv 和查询等。处理这些日志需要特定的日志系统,这些系统需要具有以下特征。
- 构建应用系统和分析系统的桥梁,并将它们之间的关联解耦。
- 支持近实时的在线分析系统和分布式并发的离线分析系统。
- 具有高可扩展性,也就是说,当数据量增加时,可以通过增加结点进行水平扩展。
目前使用最广泛的、用于系统日志采集的海量数据采集工具有 Hadoop 的 Chukwa、ApacheFlumeAFacebook 的 Scribe 和 LinkedIn 的 Kafka 等。
以上工具均采用分布式架构,能满足每秒数百 MB 的日志数据采集和传输需求。本节我们以 Flume 系统为例对系统日志采集方法进行介绍。
Flume 的基本概念
Flume 是一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统。
Flume 支持在日志系统中定制各类数据发送方,用于收集数据,同时,Flume 提供对数据进行简单处理,并写到各种数据接收方(如文本、HDFS、HBase 等)的能力。
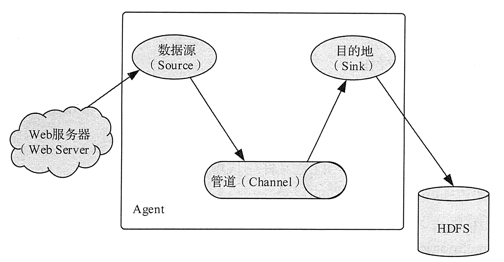
Flume 的核心是把数据从数据源(Source)收集过来,再将收集到的数据送到指定的目的地(Smk)。
为了保证输送的过程一定成功,在送到目的地之前,会先缓存数据到管道(Channel),待数据真正到达目的地后,Flume 再删除缓存的数据,如图 1 所示。