返回
2022年08月17日
-
查看C语言/C++编译器生成的汇编语言代码
长久以来,C 和 C++ 编译器都会生成汇编语言源代码,但是程序员通常看不到。这是因为,汇编语言代码只是产生可执行文件过程的一个中间步骤。幸运的是,大多数编译器都可以应要求生成汇编语言源代码文件。 例如,下表列出了 Visual Studio 控制汇编源代码输出的命令行选项。
命令行 列表文件内容 /FA 仅汇编文件 /FAc 汇编文件与机器码 /FAs 汇编文件与源代码 /FAcs 汇编文件、机器码和源代码 检查编译器生成的代码文件有助于理解底层信息,比如堆栈帧结构、循环和逻辑编码,并且还有可能找到低级编程错误。另一个好处是更加便于发现不同编译器生成代码的差异。
现在来看看 C++ 编译器生成优化代码的一种方法。由于是第一个例子,因此先编写一个简单的 C 方法 Array Sum,并在 Visual Studio 2012 中进行编译,其设置如下:
- Optimization=Disabled ( 使用调试器时需要 )
- Favor Size or Speed=Favor fast code
- Assembler Output=Assembly With Source Code
下面是用 ANSI C 编写的 arraysum 源代码:
int arraySum( int array[], int count ) { int i; int sum = 0; for(i = 0; i < count; i++) sum += array[i]; return sum; }现在来查看由编译器生成的 arraysum 的汇编代码,如下所示。
_sum$ = -8 ; size = 4 _i$ = -4 ; size = 4 _array$ = 8 ; size = 4 _count$ = 12 ; size = 4 _arraySum PROC ; COMDAT ;4 : { push ebp mov ebp, esp sub esp, 72 ; 00000048H push ebx push esi push edi ;5 : int i; ;6 : int sum = 0; mov DWORD PTR _sum$[ebp], 0 ;7 : ;8 : for(i = 0; i < count; i++) mov DWORD PTR _i$[ebp], 0 jmp SHORT $LN3@arraySum $LN2@arraySum: mov eax, DWORD PTR _i$[ebp] add eax, 1 mov DWORD PTR _i$[ebp], eax $LN3@arraySum: mov eax, DWORD PTR _i$[ebp] cmp eax, DWORD PTR _count$[ebp] jge SHORT $LN1@arraySum ;9 : sum += array[i]; mov eax, DWORD PTR _i$[ebp] mov ecx, DWORD PTR _array$[ebp] mov edx, DWORDPTR _sum$[ebp] add edx, DWORD PTR [ecx+eax*4] mov DWORD PTR _sum$[ebp], edx jmp SHORT $LN2@arraySum $LNl@arraySum: ;10 : ;11 : return sum; mov eax, DWORD PTR _sum$[ebp] ;12 : } pop edi pop esi pop ebx mov esp, ebp pop ebp ret 0 _arraySum ENDP1〜4 行定义了两个局部变量 (sum 和 i) 的负数偏移量,以及输入参数 array 和 count 的正数偏移量:
_sum$ = -8 ; size = 4
_i$ = -4 ; size = 4
_array$ = 8 ; size = 4
_count$ = 12 ; size = 49〜10 行设置 ESP 为帧指针:
push ebp
mov ebp,esp之后,11〜14 行从 ESP 中减去 72,为局部变量预留堆栈空间。同时,把将会被函数修改的三个寄存器保存到堆栈。
sub esp, 72
push ebx
push esi
push edi19 行把局部变量 sum 定位到堆栈帧,并将其初始化为 0。由于符号 _sum$ 定义为数值 -8,因此它就位于当前 EBP 下面 8 个字节的位置:
mov DWORD PTR _sum$[ebp],0
24 和 25 行将变量 i 初始化为 0,再转移到 30 行,跳过后面循环计数器递增的语句:
mov DWORD PTR _i$[ebp], 0
jmp SHORT $LN3@arraySum26〜29 行标记循环开端以及循环计数器递增的位置。从 C 源代码来看,递增操作 (i++) 是在循环末尾执行,但是编译器却将这部分代码移到了循环顶部:
$LN2@arraySum:
mov eax, DWORD PTR _i$[ebp]
add eax, 1
mov DWORD PTR _i$[ebp], eax30〜33 行比较变量 i 和 count,如果 i 大于或等于 count,则跳岀循环:
$LN3@arraySum:
mov eax, DWORD PTR _i$[ebp]
cmp eax, DWORD PTR _count$[ebp]
jge SHORT $LN1@arraySum37〜41 行计算表达式 sum+=array[i]。Array[i] 复制到 ECX,sum 复制到 EDX,执行加法运算后,EDX 的内容再复制回 sum:
mov eax, DWORD PTR _i$[ebp]
mov ecx, DWORD PTR _array$[ebp] ; array [i]
mov edx, DWORD PTR _sum$[ebp] ; sum
add edx, DWORD PTR [ecx+eax*4]
mov DWORD PTR _sum$[ebp], edx42 行将控制转回循环顶部:
jmp SHORT $LN2@arraySum
43 行的标号正好位于循环之外,该位置便于作为循环结束时进行跳转的目标地址:
$LN1@arraySum:
48 行将变量 sum 送入 EAX,准备返回主调程序。52〜56 行恢复之前被保存的寄存器,其中,ESP 必须指向主调程序在堆栈中的返回地址。
mov eax, DWORD PTR _sum$[ebp]
; 12 : }
pop edi
pop esi
pop ebx
mov esp, ebp
pop ebp
ret 0
_arraySum ENDP可以写出比上例更快的代码,这种想法不无道理。上例中的代码是为了进行交互式调试,因此为了可读性而牺牲了速度。如果针对确定目标编译同样的程序,并选择完全优化,那么结果代码的执行速度将会非常快,但同时,程序对人类而言基本上是无法阅读和理解的。
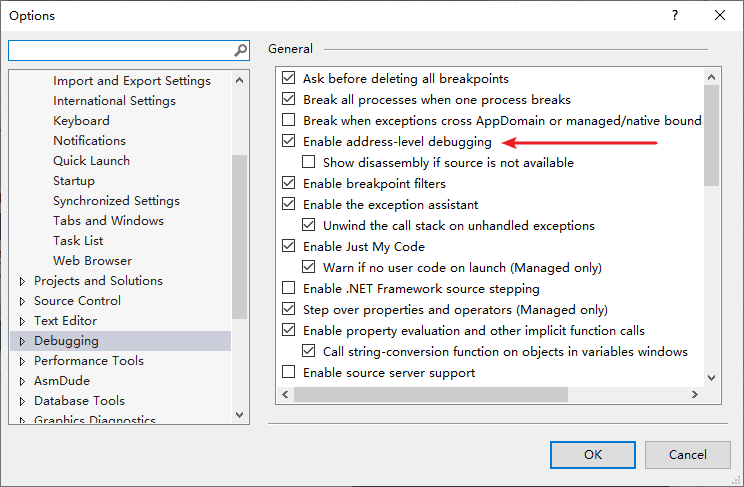
调试器设置
用 Visual Studio 调试 C 和 C++ 程序时,若想查看汇编语言源代码,就在 Tools 菜单中选择 Options 以显示如下图的对话框窗口,再选择箭头所指的选项。上述设置要在启动调试器之前完成。接着,在调试会话开始后,右键点击源代码窗口,从弹出菜单中选择 Go to Disassembly。