TensorFlow分布式详解
每次 TensorFlow 运算都被描述成计算图的形式,它允许结构和运算操作配置所具备的自由度能够被分配到各个分布式节点上。计算图可以分成多个子图,分配给服务器集群中的不同节点。
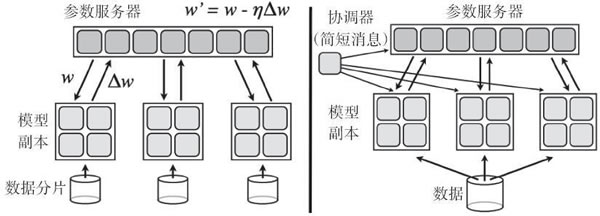
强烈推荐读者阅读论文“Large Scale Distributed Deep Networks”,本文的一个重要成果是证明了分布式随机梯度下降算法(SDG)可以运行,在该算法中,有多个节点在数据分片上并行工作,通过向参数服务器发送更新来异步独立更新梯度。论文摘要引用如下:实验揭示了一些关于大规模非凸优化的令人惊喜的结果。首先,很少应用于非凸问题的异步 SGD 在训练深度网络方面效果很好,特别是在结合 Adagrad 自适应学习率时。
这篇论文本身的一个照片可以很好地解释这一点:
")
及其原理详解")
")
发表评论