搜索引擎抓取网页的流程
搜索引擎对网页的抓取实质上就是搜索蜘蛛(Spider)或机器人(Robot)在整个互联网平台上进行信息的采集和抓取,这也是搜索引擎最基本的工作。
搜索引擎蜘蛛/机器人采集的力度直接决定了搜索引擎前端检索器可提供的信息量及信息覆盖面,同时影响反馈给用户检索查询信息的质量。所以,搜索引擎本身在不断设法提高其数据采集/抓取及分析的能力。
本文将着重介绍搜索引擎抓取页面的流程及方式。
1. 页面收录/抓取流程
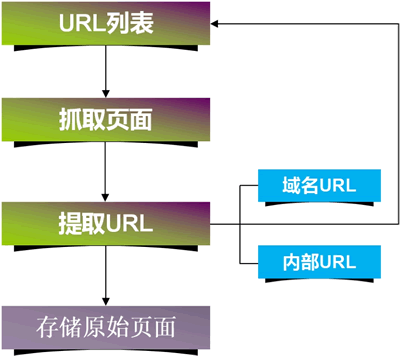
在整个互联网中,URL 是每个页面的入口地址,同时搜索引擎蜘蛛程序也是通过 URL 来抓取网站页面的,整个流程如图1所示。



发表评论